
Android中使用SQLite数据库存储数据,重点理解CRUD使用。
SQLite简介
SQLite优点
- 轻量级: 使用 SQLite 只需要带一个动态库,就可以享受它的全部功能,而且那个动态库的尺寸很小。
- 独立性: SQLite 数据库的核心引擎不需要依赖第三方软件,也不需要所谓的“安装”。
- 隔离性:SQLite 数据库中所有的信息(比如表、视图、触发器等)都包含在一个文件夹内,方便管理和维护。
- 跨平台:SQLite 目前支持大部分操作系统,不至电脑操作系统更在众多的手机系统也是能够运行,比如:Android和IOS。
- 多语言接口:SQLite 数据库支持多语言编程接口。
- 安全性:SQLite 数据库通过数据库级上的独占性和共享锁来实现独立事务处理。这意味着多个进程可以在同一时间从同一数据库读取数据,但只能有一个可以写入数据。
- 弱类型的字段:同一列中的数据可以是不同类型
SQLite数据类型
SQLite具有以下五种常用的数据类型:
| 存储类 | 存储类 |
|---|---|
| NULL | 值是一个 NULL 值 |
| INTEGER | 值是一个带符号的整数,根据值的大小存储在 1、2、3、4、6 或 8 字节中 |
| REAL | 值是一个浮点值,存储为 8 字节的 IEEE 浮点数字 |
| TEXT | 值是一个文本字符串,使用数据库编码(UTF-8、UTF-16BE 或 UTF-16LE)存储 |
| BLOB | 值是一个 blob 数据,完全根据它的输入存储 |
Boolean 数据类型
SQLite 没有单独的 Boolean 存储类。相反,布尔值被存储为整数 0(false)和 1(true)。
Date 与 Time 数据类型
SQLite 没有一个单独的用于存储日期和/或时间的存储类,但 SQLite 能够把日期和时间存储为 TEXT、REAL 或 INTEGER 值。
SQLite使用
1.定义schema
schema就是数据库对象的集合,这个集合包含了各种对象如:表、视图、存储过程、索引等。
操作步骤
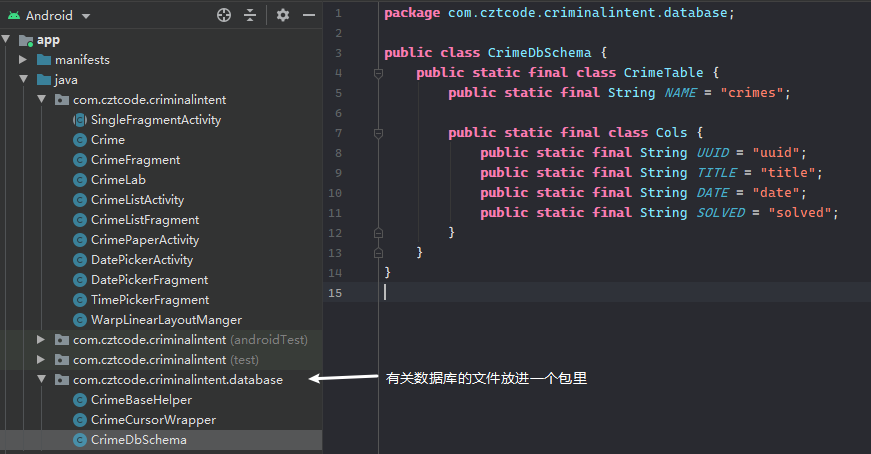
首先创建一个模式,这里新建了一个CrimeDbSchema。
按照逻辑关系,我们创建了一个名为CrimeTable的内部类作为表,定义表名。
在表中定义 型(表头),创建内部类Cols表示列。
2.定义初始数据库
创建一个类继承SQLiteOpenHelper,需要实现其三个方法:
- 构造方法:需要给SQLiteOpenHelper传递四个参数:(上下文,数据库名,游标工厂(通常为null),当前数据库版本号);
- onCreate(): 表的创建,初始化操作
- onUpgrade(): 表升级
创建自定义class继承SQLiteOpenHelper,介绍在图中。
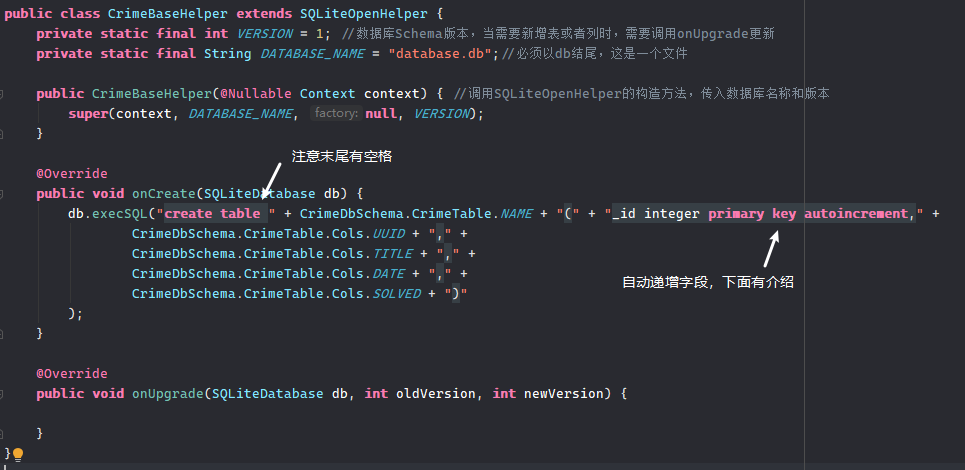
主码就是:_id
关于自动递增字段:
SQLite 的 AUTOINCREMENT 是一个关键字,用于表中的字段值自动递增。我们可以在创建表时在特定的列名称上使用 AUTOINCREMENT 关键字实现该字段值的自动增加。
关键字 AUTOINCREMENT 只能用于整型(INTEGER)字段。详细介绍
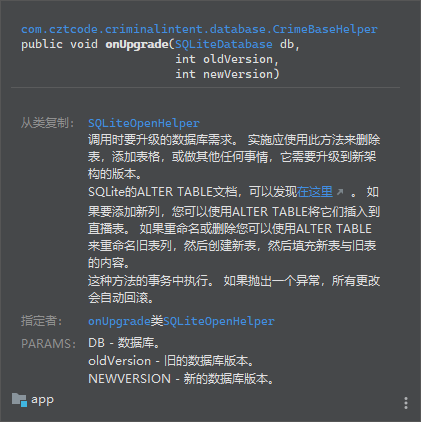
关于onUpgrade方法:
虽然暂时用不上,但这个方法是用于添加表或者列的
创建数据库遵循的方法
- 确认目标数据库是否存在
- 若不存在,首先创建数据库,然后创建数据表并初始化数据
- 若存在,检查Schema是否为最新版本
- 如果是旧版本,就先升级到最新版本
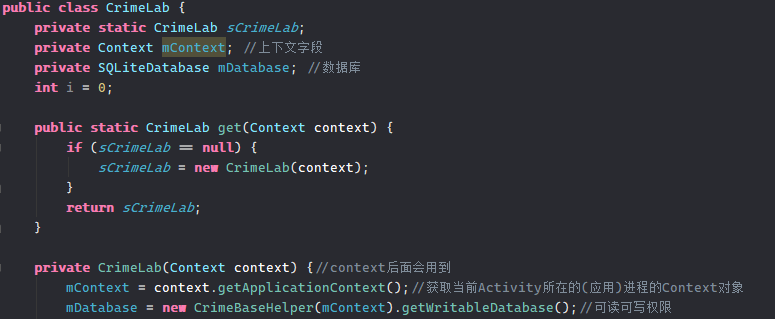
3.创建数据库
介绍在注释里
写入数据
ContentValues类简介
ContentValues和Hash Table都是一种存储的机制。两者的区别在于,contentValues只能存储基本类型的数据,String,int之类的,不能存储对象,只能用于SQLite中,而Hash Table却可以存储对象。
把数据插入数据库中时,首先要有一个ContentValues的对象:
ContentValues contentValues = new ContentValues();
contentValues.put(key,values);
SQLiteDataBase sdb;
sdb.insert(database_name,null,initialValues);成功插入则返回记录的id,否则返回-1。
建立键值对对应关系
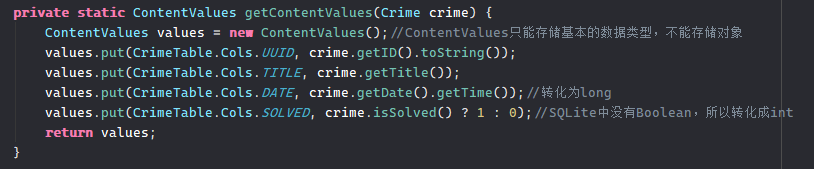
将Crime的值根据ContentValues添加的对应关系添加进数据库中

更新数据

我翻译一下:传入要更新的对象。获取对象类型与数据库型之间的对应关系,也就是ContentValues。还要将待查询的UUID转化为String类型,因为SQLlite里不存UUID类型的数据。
重点:防止SQL注入(我感觉是)
关于SQL注入我写过两篇文章,有兴趣可以先去看看
SQLite的防止SQL注入方式和Java相同,使用?代替实际值。当数据库执行时,非?的语句会被编译。在编译后再将?处的值引入完成查询。这样有效避免了查询这种
select count(1) from students where name='张三' or '1=1' 会把整个数据库都显示出来的情形,因为?处语句根本没有编译执行。

ps:有人可能会问,insert的时候怎么不防止sql注入?我感觉可以,可能书上没写。调用insert和update都是等于系统再去调用数据库的方法,拼接上where等语句。去查了下源码,到这里就进不去了,但是确实没有对于?的处理,应该是封装在SQLite的内部。
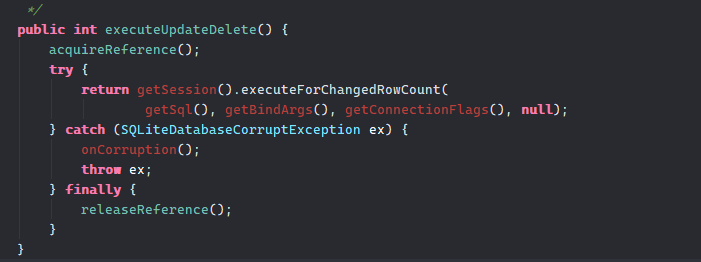
在网上查到一种防止intsert SQL注入的方式,和update原理相同。
String sql = " insert into " + TABLE_NAME + "(message,time) values(?,?)";
Object[] args = {message,time};
db.execSQL(sql,args);
dbClose();调用updateCrime
不要忘记在onPause处添加更新语句
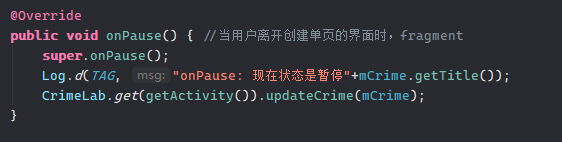
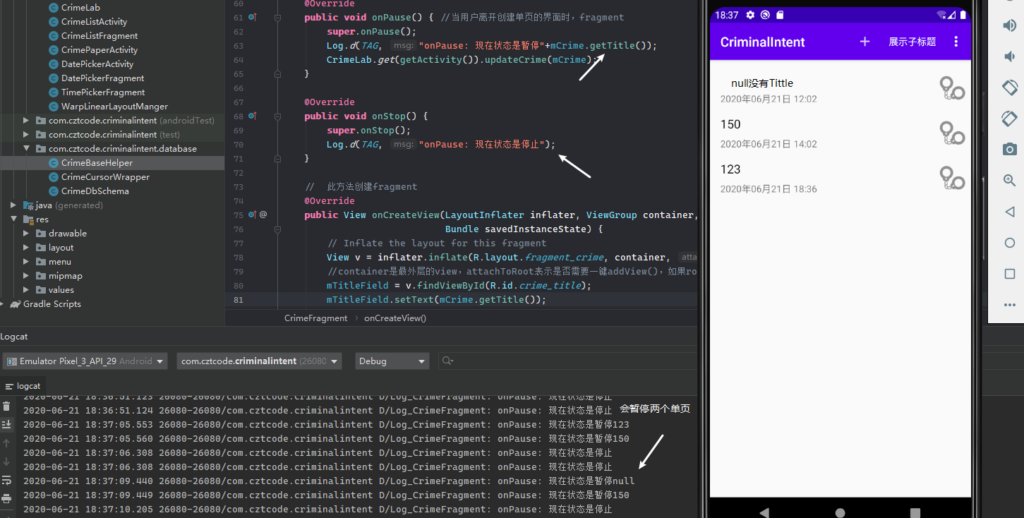
其实书中之前说过,当一个Fragment不可见时调用onPause和onStop。为了保险起见(onStop有可能不调用,但onPause一定调用),写在了onPause里,关于Fragment的生命周期,我也有过一篇文章说明:Activity与Fragment的生命周期
使用logcat看实际调用情况,发现了一个很有趣的地方。FragmentManger会保留最近两个的Fragment,并在当前Fragment不可见时。为当前Fragment和之前保存的一个Fragment共同调用onStop。
查询数据
我们需要使用cursor(游标),通过游标帮助我们查询。
继承CursorWrapper类
首先继承这个类,添加要从哪些列取得哪些数据,并返回一个实例。注意此处的getString和getLong是CursorWrapper内的方法,用于返回对于列号中的数据。
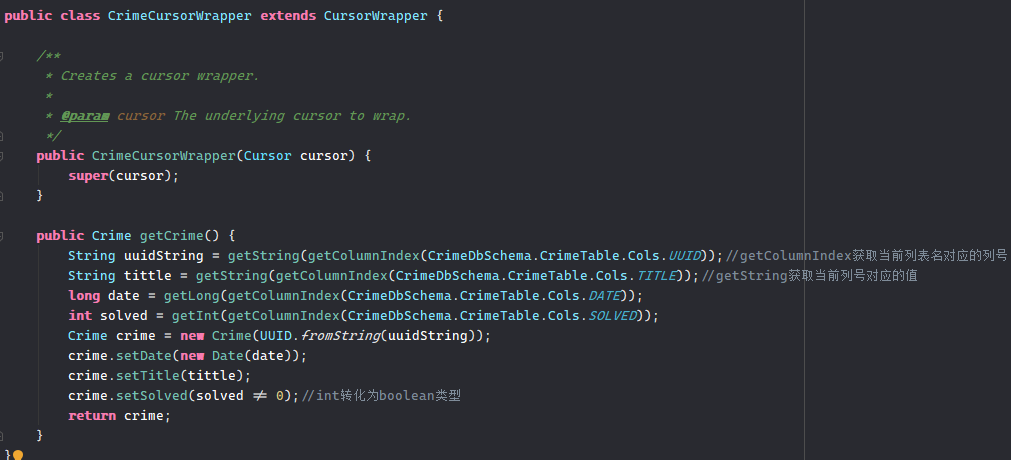
在CRUD(CrimeLab)中调用初始化Cursor。
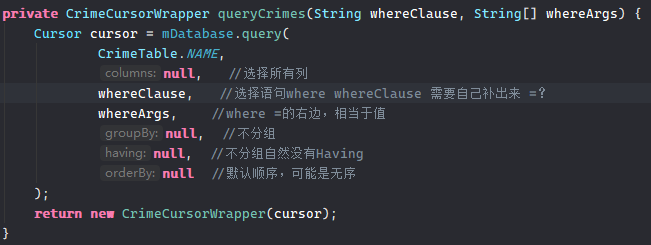
这样我们在查询时,只需使用CrimeCursorWrapper实例化出一个cursor,再利用cursor的循环操作就可以遍历出所有信息了。
例子:获取全部列表信息
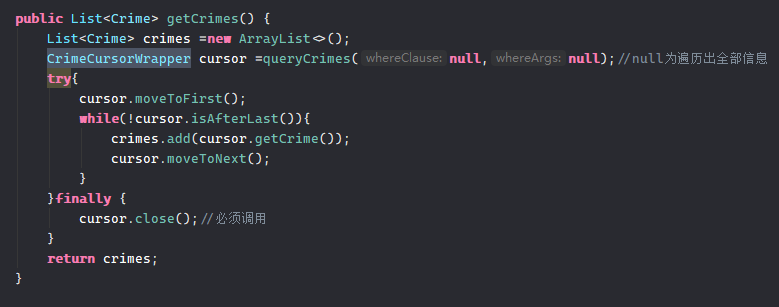
注意,在执行到CrimeCursorWrapper这句时数据已经在SQLite中查询完了,下面使用move等方法都是对cursor内查询到的数据的操作。
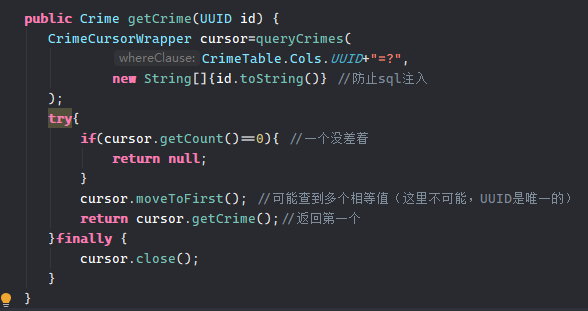
例子:根据uuid获取信息
这里uuid就是相当与主码,因为具有唯一性。(实际主码是_id前面说了)
刷新模型层数据
为什么要干这个事呢,因为当你对数据库一顿操作出来并保存后。发现原来的视图并没有更新。因为数据不可能在使用时都去数据库取,肯定有缓存。比如我建立了一个数组保存从数据库取出来的数据,它的初始化是在视图启动时。当我数据库更新后这个数组并没有变,所以我们需要更新UI。
我写一个set方法
public void setCrimes(List<Crime> crimes){
mCrimes =crimes;
}这里重新更新当前的Crime数组
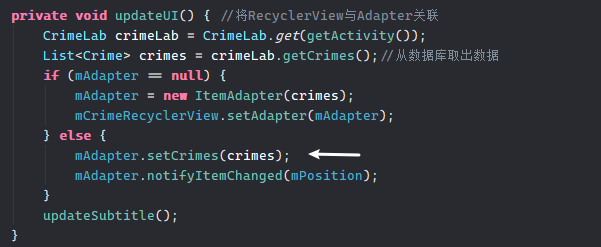
这个updateUI是在Fragment运行时调用的,写在了onResume里。同时在onCreateView中也会调用(ViewHolder和Adapter绑定)。
删除数据
删除很简单,和更新的方式类似。使用主码或者候选码找到项目调用delete删除,注意防止sql注入。

实现效果
