
错误率: 把分类错误的样本数占样本总数的比例称为错误率
精确率:1-错误率
过拟合:把样本自身的一些特点当成所有样品都有的一般性质
欠拟合:样本的一些性质尚未学好
训练集与测试集划分:
留出法:随机样本,取其中的2/3~4/5为训练集。分层采样: 则保留类别比例的采样方式。 如通过对 进行分层采样而获得含 70% 样本的训练集 和含 30% 样本的测试集 包含 500 个正例、 500 个反例,则分层采样得到的 应包含 350 个正例、 350 个反例。
交叉验证法:将样本分为k个子集,其中k-1用于训练集,共进行k次训练。
留一法:k个样本分为k个子集,每次只用一个验证,是交叉验证法的特例,留一法结果往往认为比较准确,受到样本规模影响产生误差比较小。
自助法:自助法为了解决样本规模不一致造成的误差,每次从样本集D中取出一个样本放入D`作为样本,再将该样本放回D,这样m次采样中仍有近1/3的数据作为测试集。自助法在样本集较小时使用, 自助法产生的数据集改变了初始数据集的分布,这会引入估计偏差。
最终模型: 模型选择完成后,学习算法和参数配置己选定,此时应该用数据集重新训练模型.这个模型在训练过程中使用了所有样本,这才是我们最终提交给用 户的模型 。
分类混淆矩阵:
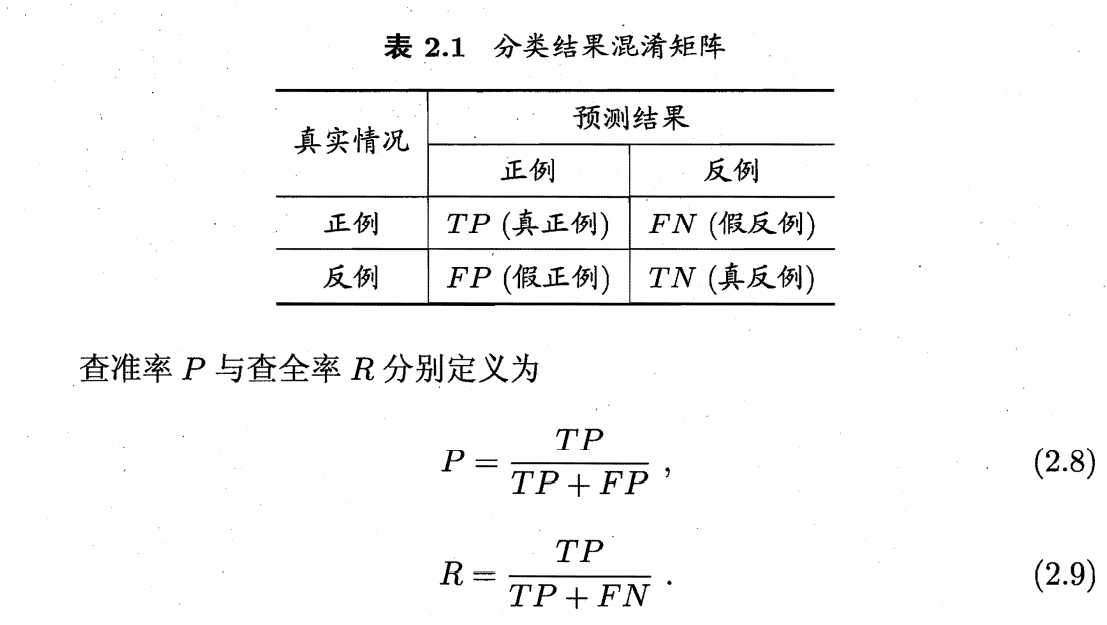
查准率和查全率是一对矛盾的度量。一般来说,查准率高时,查全率往往偏低。而查全率高时,查准率往往偏低。通常只有在一些简单任务中 才可能使查全率和查准率都很高.
比较两个模型的性能
P-R曲线
P:Precision 查准率
R: Recall 查全率(也叫召回率)
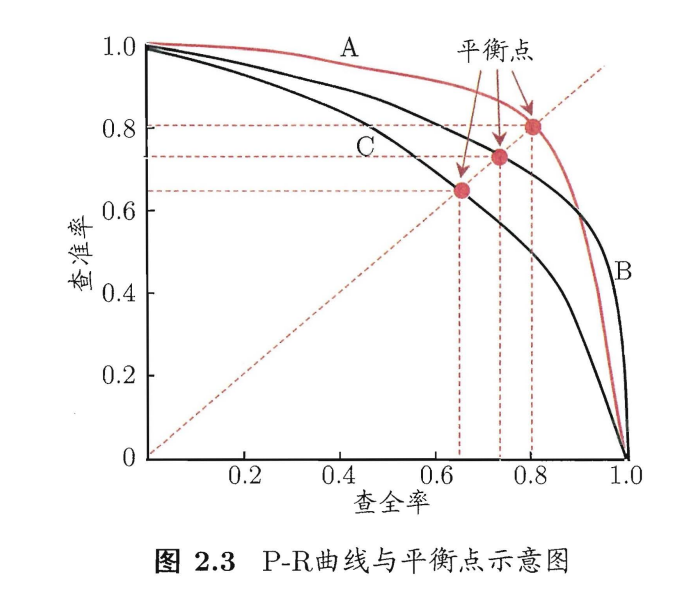
若一个学习器的 P-R 曲线被另一个学习器的曲线完全”包住 则可断言后者的性能优于前者。
平衡点(BEP):查准率=查全率时的取值。
F1度量:
F1是PR的调和平均数,整理后得到下面这个式子
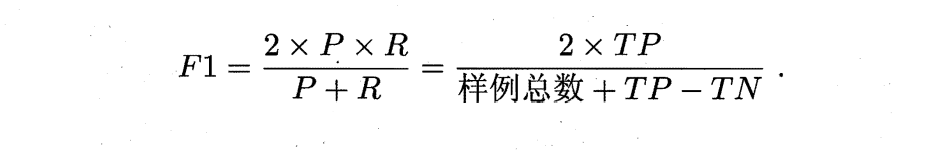

在n个样本上获得多个二分类混淆矩阵,最后计算的时候取平均,取平均的时候可以直接F1取平均值,也可以计算一个平均的二分类混淆矩阵再取平均,得到微F1。
ROC受试者工作特征:很多机器学习产生的是一个值,这个值与分类阈值比较,大于归为正类,反之归为反类。若重视查准率,则阈值比较高。若重视查全率,则阈值比较低。ROC以真正率TPR为纵坐标,假正例率FPR为横坐标作图。

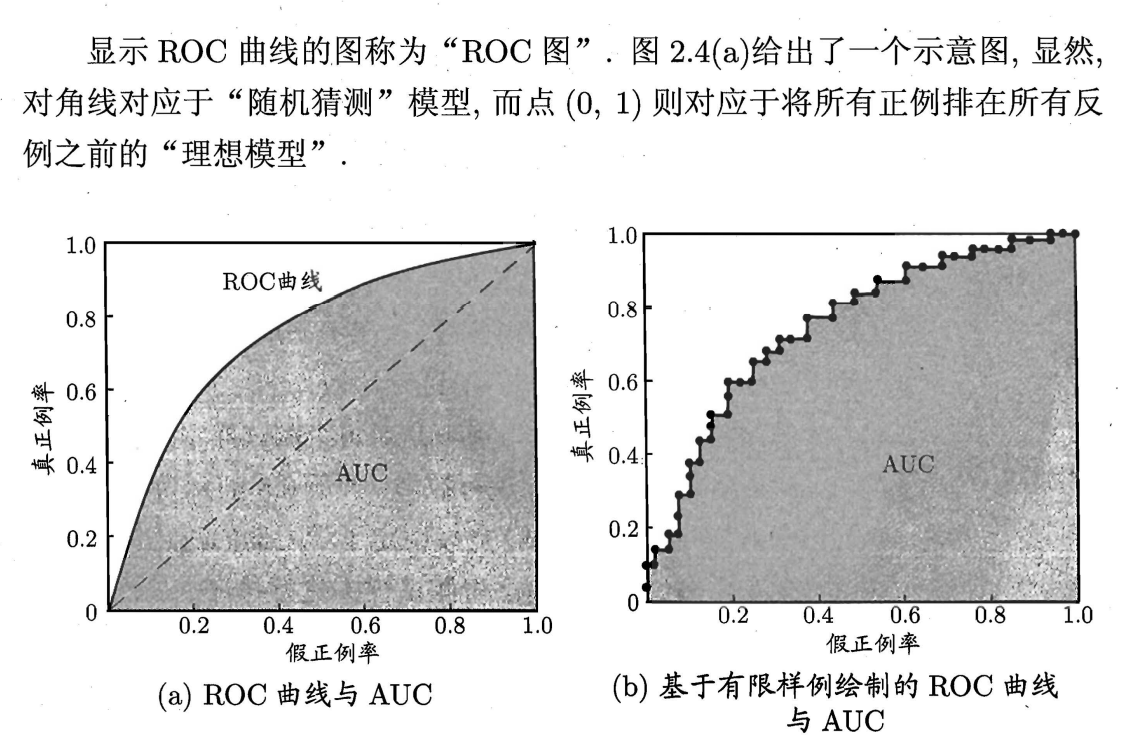
机器学习器的比较时, P-R 图相似, 一个学习器的 ROC 曲线被另 习器的曲线完全”包住”, 则可断言后者的性能优于前者;若两个学习 ROC 曲线发生交叉,则难以-般性地断言两者孰优孰 此时如果一定要进 行比较 则较为合理的判据是 比较 ROC 线下 的面积。
PR和ROC曲线应用范围:
1.当正负样本比例差不多的时候,两者区别不大。
2.PR曲线比ROC曲线更加关注正样本,而ROC则兼顾了两者。
3.AUC越大,反映出正样本的预测结果更加靠前。(推荐的样本更能符合用户的喜好)
4.当正负样本比例失调时,比如正样本1个,负样本100个,则ROC曲线变化不大,此时用PR曲线更加能反映出分类器性能的好坏。
5.PR曲线和ROC绘制的方法不一样。
代价曲线 :FP和FN的错误代价是不同的,代价曲线估计不同算法的代价。

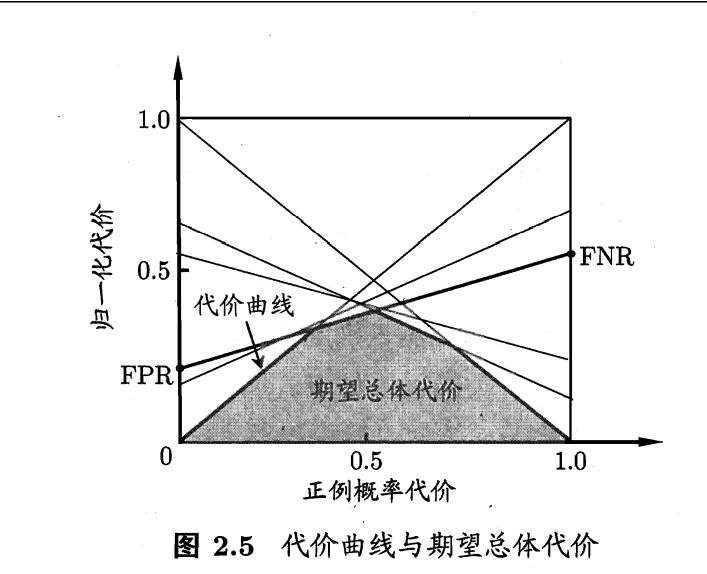
代价曲线的变量是Pcost(归一化的p,代表阈值),我们想知道取不同阈值对于两类错误的代价是多少,所以每取一个p,对应纵轴一个代价,围成的面积构成代价的期望。