
HashSet中的add方法
hash方法与hashCode
hash方法在HashMap中,用于生成对象的hash值。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}int类型是32位的, h ^ h >>> 16 其实就是将hashCode的高16位和低16位进行异或, 这充分利用了高半位和低半位的信息, 对低位进行了扰动, 目的是为了使该hashCode映射成数组下标时可以更均匀, 详细的解释可以参考这里.
调用了hashCode方法,详细的解释如下。
hashCode()方法给对象返回一个hash code值。
- 在一个Java应用的执行期间,如果一个对象提供给equals做比较的信息没有被修改的话,该对象多次调用
hashCode()方法,该方法必须始终如一返回同一个integer。 - 如果两个对象根据
equals(Object)方法是相等的,那么调用二者各自的hashCode()方法必须产生同一个integer结果。 - 并不要求根据
equals(java.lang.Object)方法不相等的两个对象,调用二者各自的hashCode()方法必须产生不同的integer结果。然而,程序员应该意识到对于不同的对象产生不同的integer结果,有可能会提高hash table的性能。
大量的实践表明,由Object类定义的hashCode()方法对于不同的对象返回不同的integer。
可以试验一下,比如下段代码输入相同的String对象,输出是一样的
class Test {
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
public static void main(String[] args) {
String a = "123";
String b = "123";
System.out.println(hash(a));
System.out.println(hash(b));
}
}输出结果均为48690
了解了hash,现在可以看看add方法的实现了
HashSet中的add方法
无冲突的add
首先创建一个HashSet对象,调用add方法,仅add了一个jim。
import java.util.HashSet;
public class Test2 {
public static void main(String[] args) {
HashSet<String> names = new HashSet<String>();
//调用构造方法时,创建HashMap集合对象
names.add("Jim");
//向HashMap集合的key存值,HashMap value是一个常量 Object
}
}
查看add的源代码可以发现,add中调用了map中的put方法
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}put方法又调用了putVal方法
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}注意这里用了hash方法
putVal再进去
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}显示不是很方便,我把图片发出来(建议你看的时候把这张图保存下来,下面讲解代码是截取的片段,整体看更易于理解)
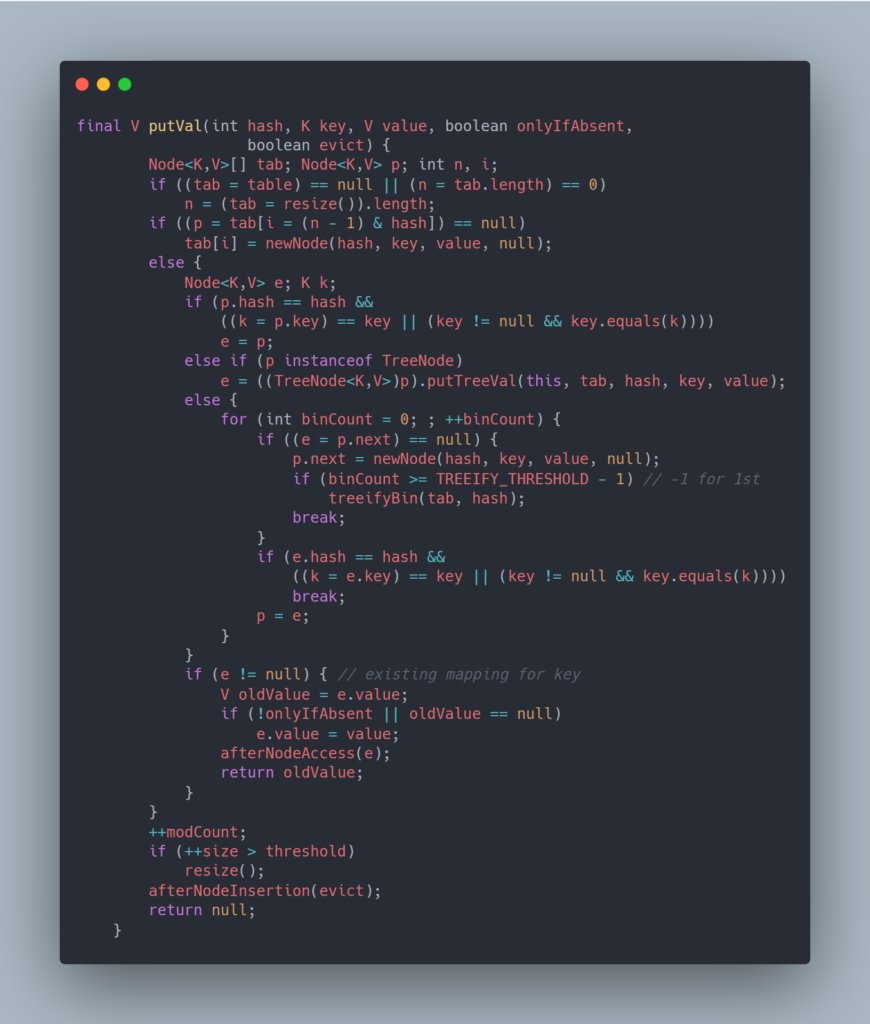
主要看下面这一部分

参数分别为
- hash:add对象的hash值
- key:add的对象
- value:待存储的值(map)
- onlyIfAbsent:为true时,当key已经存在了,覆保留原有值 false时覆盖
- evict:区分当前是否为构造模式
逐行分析
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;判断table是不是空的,当第一次使用add时,使用resize()方法初始化table。Map默认大小为16,加载因子0.75 。
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);n为当前table的长度,(n – 1) & hash用来计算下标,同时用到了数组长度和hash计算,避免重复。如果当前tab中在i处没有存过,则存进去。否则进入else,即出现了重复值。
有冲突的add
现在向add里添加两个Jim
import java.util.HashSet;
public class Test2 {
public static void main(String[] args) {
HashSet<String> names = new HashSet<String>();
//调用构造方法时,创建HashMap集合对象
names.add("Jim");
names.add("Jim");
//向HashMap集合的key存值,HashMap value是一个常量 Object
}
}
结果names里只有一个Jim,毕竟是Set的特性嘛。
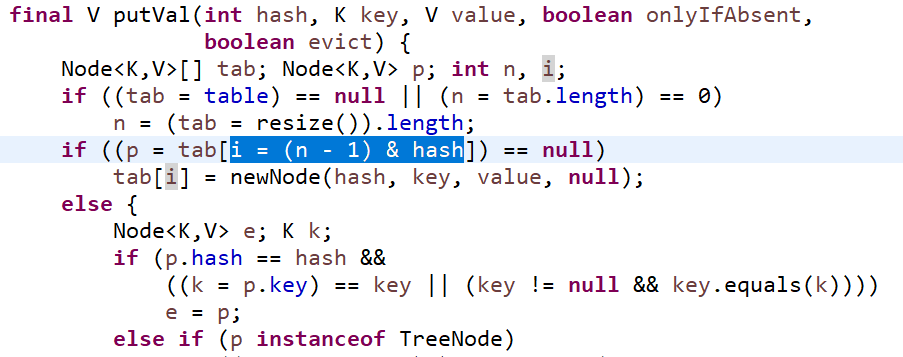
这里会先计算hash值,也就是说传进来的两个相同的对象的hash值冲突,不会再开辟新空间存进去,也就实现了Set中不会有重复的特点。
冲突有两种情况
- tab[i]的位置在此之前存的是Jim
- tab[i]的位置在此之前存的不是Jim,但hash值碰巧相同
ps:好的hashCode方法会让第二种冲突情况发生的尽可能少
看else往下的代码
if (p.hash == hash &&((k = p.key) == key ||(key != null && key.equals(k))))
e = p;p指的是当前冲突的对象,在这个例子中指的是第一个Jim。如果p的hash值与当前对象的hash值相同(确定是第一种冲突),且他们的对象也相同。说明添加进一摸一样的元素,而Set中又不许有相同元素,添加失败。
第二个条件,如果对象不为null,且对象的值和冲突对象的值相同(equals),说明当前出现了不一样的对象计算出同一个hash值的情况(后面会详细说),在这种情况下,需要有解决冲突的算法,让第二个后来的对象计算出新的hash值。
我该怎么实现这个??
现在我创建了一个Student类,并想存入相同的对象,在我看来id相同就是说明这是一个对象,那我调用hashSet类会出现什么情况呢?
package Test;
import java.util.HashSet;
class Student {
String id;
Student(String id) {
this.id = id;
}
}
public class Test {
public static void main(String[] args) {
HashSet<Student> stu = new HashSet<>();
stu.add(new Student("111"));
stu.add(new Student("111"));
System.out.println(stu);
}
}
也就是说,我们需要使用hashSet方法添加相同的对象时,即使两个对象的值完全相同,使用hashSet还是添加进两个对象。因为这两个对象调用hashCode方法计算出的值是不同的。
重写hashCode
既然默认的hashSet不能实现,那就重写hashCode的方法,让它知道如果id相同这两个对象就会被视为一个,而不是用地址去算hashCode。
@Override
public int hashCode() {
return id.hashCode();
}重写之后程序会怎样运行呢?

额,set是坏了吗?
当然不是!接下来看看到底发生了什么
这时候进行这句判断时,hashCode百分百不是null。因为返回的是id的hashCode。这时侯进入else
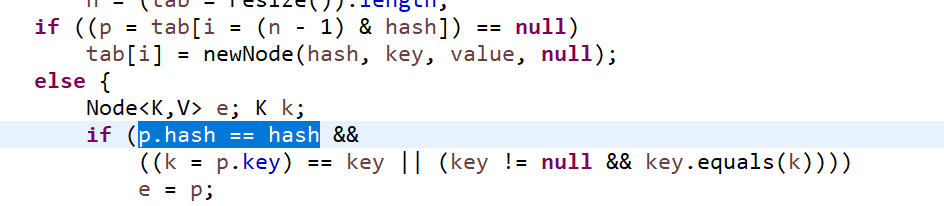
先判断hash值,已经相同了。接下来比较地址 (k = p.key) == key就是判断当前要存入的对象与之前的对象到底是不是一个,是一个的话地址肯定相同。我new出来两个id为111的对象,地址肯定不同。再看看如果地址也相同会执行什么,e=p; 什么意思呢,e就是一个临时值。上面列过putVal的参数,其中有一个onlyIfAbsent,这个值为true时,当key已经存在了,覆保留原有值;false时覆盖。
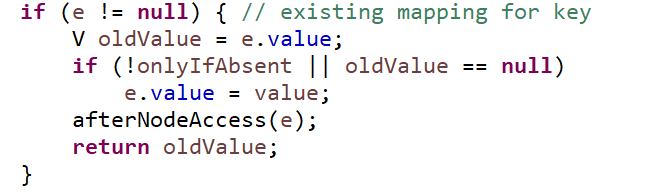
那我们的目的就是要执行e=p,这样就不会存入两个值。
if (p.hash == hash && ((k = p.key) == key || (key != null &&key.equals(k))))
e = p;可以看到if有两个判断,||之后使用equals方法判断,如果相同同样不会存入两个值!
object中equals方法默认比较的是地址

那就有解决办法了,同时重写hashCode方法和equals方法,就可以实现目标。
重写hashCode方法和equals方法
package Test;
import java.util.HashSet;
class Student {
String id;
Student(String id) {
this.id = id;
}
@Override
public int hashCode() {
return id.hashCode();
}
@Override
public boolean equals(Object obj) {
if(obj instanceof Student) {
Student stu=(Student) obj;
return this.id.equals(stu.id);
}
return false;
}
}
public class Test {
public static void main(String[] args) {
HashSet<Student> stu = new HashSet<>();
stu.add(new Student("111"));
stu.add(new Student("111"));
System.out.println(stu);
}
}重写之后执行结果

也可以用eclipse自动生成hashCode和equals方法
自动添加很完美,想到了很多情况。
package Test;
import java.util.HashSet;
class Student {
String id;
Student(String id) {
this.id = id;
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + ((id == null) ? 0 : id.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Student other = (Student) obj;
if (id == null) {
if (other.id != null)
return false;
} else if (!id.equals(other.id))
return false;
return true;
}
}
public class Test {
public static void main(String[] args) {
HashSet<Student> stu = new HashSet<>();
stu.add(new Student("111"));
stu.add(new Student("111"));
System.out.println(stu);
}
}重新计算hash值的方发这里暂时不展开了,以后学完还会更新。